À l’ère de l’infobésité, nous stockons des milliers de notes, PDF et articles que nous ne relisons jamais. Comme le souligne Tiago Forte, expert en productivité et auteur de Building a Second Brain :
« Votre cerveau est fait pour avoir des idées, pas pour les stocker. »
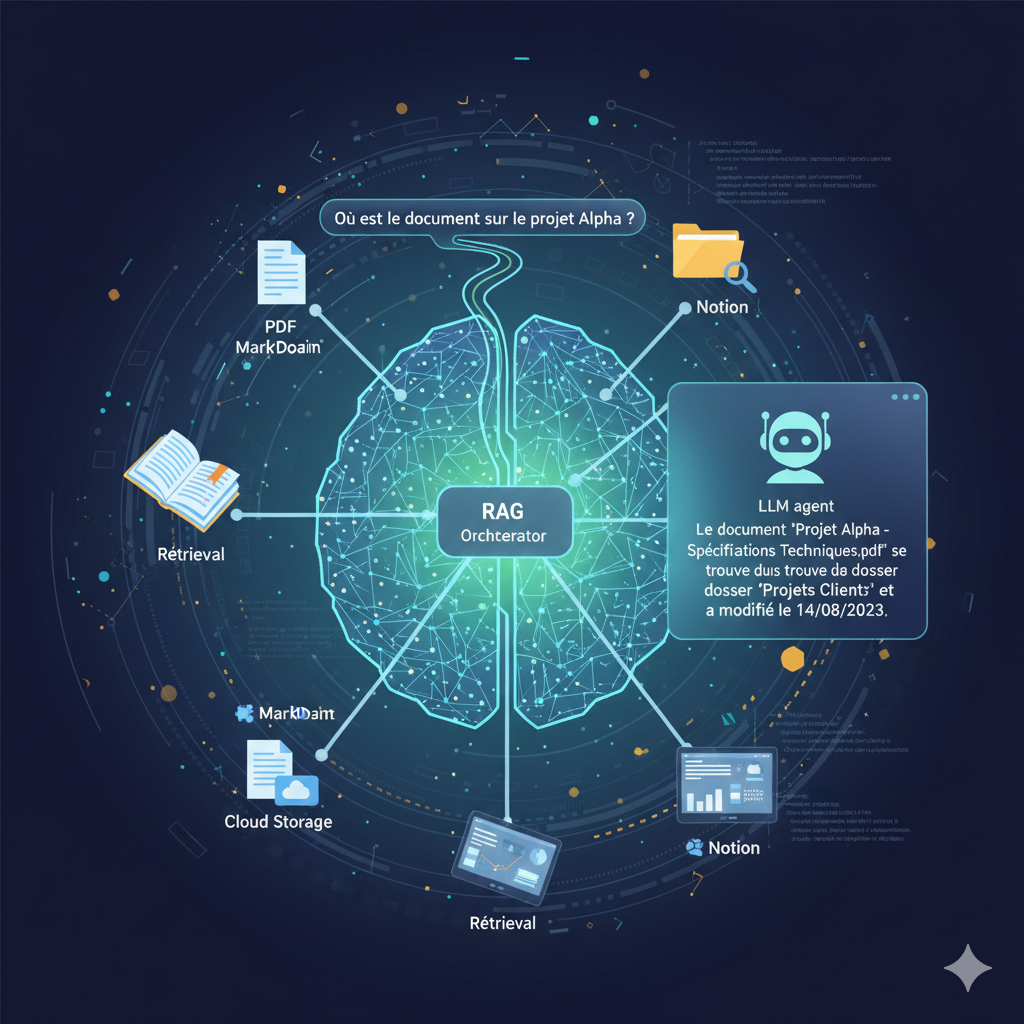
Et si vous pouviez converser avec ce stock de connaissances ? Grâce à la technologie RAG (Retrieval-Augmented Generation), il est désormais possible de créer un « Cerveau Numérique » personnalisé, capable de répondre à vos questions en se basant exclusivement sur vos données.
Qu’est-ce que le RAG et pourquoi est-ce une révolution ?
Le RAG, ou Génération Augmentée par Récupération, est une architecture qui connecte un grand modèle de langage (LLM) comme GPT-4 ou Llama 3 à vos propres sources de données.
Le problème des LLM classiques
Les modèles d’IA standards souffrent de deux limites majeures : la date de coupure de leurs données et l’absence de contexte privé. Andrej Karpathy, cofondateur d’OpenAI, compare souvent les LLM à des moteurs de raisonnement :
« Considérez les LLM non pas comme des bases de données de connaissances, mais comme des processeurs de texte qui ont besoin d’un accès à une bibliothèque externe pour être précis. »
La solution RAG
Le RAG agit comme ce bibliothécaire. Lorsque vous posez une question, le système cherche d’abord les passages pertinents dans vos documents, puis les donne au LLM pour qu’il rédige une réponse. C’est la clé pour éliminer les « hallucinations ».
Les composants essentiels de votre Cerveau Numérique
Pour construire ce système, vous aurez besoin de quatre piliers :
- Vos données (La source) : PDF, fichiers Markdown (Obsidian/Notion), documents Word.
- Un modèle d’Embeddings : Un algorithme qui transforme le texte en vecteurs mathématiques.
- Une Vector Database : Un espace de stockage spécialisé comme Pinecone ou ChromaDB.
- L’Orchestrateur : Un outil comme LangChain ou LlamaIndex.
Étape 1 : Préparation et « Chunking » des données
On ne peut pas envoyer 500 pages d’un coup à une IA. Il faut découper vos documents en petits morceaux appelés « chunks ».
- Conseil d’expert : Optez pour des segments de 500 à 1000 jetons (tokens) avec un léger chevauchement (overlap) pour ne pas perdre le sens entre deux paragraphes.
Étape 2 : Création des Embeddings et stockage
Chaque segment de texte est traduit en langage machine (vecteurs). Comme l’explique Jay Alammar, vulgarisateur renommé de l’IA :
« Les embeddings permettent à l’ordinateur de comprendre la proximité sémantique. « Roi » et « Reine » seront proches dans cet espace mathématique, même s’ils ne partagent pas les mêmes lettres. »
Vous stockerez ensuite ces vecteurs dans votre Vector Database. Pour une confidentialité totale, utilisez Ollama pour faire tourner vos modèles localement.
Étape 3 : La phase de « Retrieval » (Récupération)
C’est le cœur du système. Quand vous posez une question :
- Votre question est convertie en vecteur.
- Le système cherche dans la base les 3 ou 5 « chunks » les plus proches mathématiquement.
- Ces extraits sont fournis à l’IA comme contexte.
Étape 4 : La génération de la réponse
L’orchestrateur envoie au LLM un « prompt » structuré :
« Tu es une extension de mon cerveau. Voici des extraits de mes notes : [Extraits]. En te basant uniquement sur ces infos, réponds à : [Votre Question]. »
Les outils pour commencer sans coder
- AnythingLLM : Une solution tout-en-un pour transformer vos dossiers locaux en moteur de recherche intelligent.
- NotebookLM (Google) : Pour analyser des sources spécifiques et générer des résumés.
- GPTs personnalisés : La solution simple d’OpenAI pour uploader vos fichiers.
Pourquoi construire son propre système ?
1. Précision chirurgicale
Le RAG réduit drastiquement les erreurs. Yann LeCun, chef de l’IA chez Meta, affirme d’ailleurs :
« Pour que l’IA soit réellement utile, elle doit être capable de raisonner sur des données fraîches et spécifiques à l’utilisateur, ce que le RAG permet aujourd’hui. »
2. Souveraineté des données
En utilisant des modèles open-source, vous gardez le contrôle total sur votre propriété intellectuelle. Vos secrets industriels ou personnels ne servent pas à entraîner les modèles des Big Tech.
3. Gain de productivité massif
Imaginez retrouver une clause spécifique dans un contrat de 2018 ou une idée de génie notée sur un coin de page il y a trois ans, en une seule commande vocale.
Conclusion : Un investissement pour l’avenir
Construire un RAG n’est pas qu’un projet technique, c’est une nouvelle façon de gérer son savoir. Comme le dit souvent l’entrepreneur Naval Ravikant :
« L’outil le plus puissant de l’avenir sera celui qui permettra d’amplifier l’intellect humain individuel. »
En centralisant vos connaissances dans une structure exploitable par l’IA, vous transformez une archive passive en un partenaire de réflexion actif.
Questions fréquentes (FAQ)
Le RAG est-il payant ? Cela dépend. Utiliser GPT-4 via API a un coût, mais des alternatives 100% gratuites existent avec des modèles comme Mistral ou Llama 3 tournant sur votre propre machine.
Est-ce difficile à maintenir ? Le plus dur est l’organisation initiale de vos données. Une fois la base vectorielle créée, l’ajout de nouveaux documents peut être automatisé.
Le RAG remplace-t-il la prise de notes ? Au contraire, il la valorise. Plus vos notes sont de qualité, plus votre « Cerveau Numérique » sera puissant.